
데이터분석을 할 때 가장 방해되는 요소 중 하나가 Null값 입니다. 특히, 숫자의 계산이 필요한 경우 null값은 계산의 부정확성을 증가시킵니다. 임의로 값을 변경할 경우 정확한 분석을 할 수 없기 때문에 평균값을 입력하는 듯 합리적인 기준을 설정하여 Null 값을 변경해야합니다. 또는, 합리적인 기준에 따라 null값을 제거할 수 있습니다. 데이터프레임에서 null값을 다루는 방법을 알아보겠습니다.
CSV 파일 불러오기
df = pd.read_csv('movie_scores.csv')
Jupyter Notebook을 사용하는 경우, 불러오고자 하는 CSV 파일이 Jupyter Notebook 파일과 같은 폴더에 있도록 해주세요.
df라고 이름을 지정하고 "movie_scores"라는 csv 파일을 불러옵니다.
Notnull( )과 Isnull( ) 함
df[df['first_name'].notnull()]

notnull 함수를 사용하면 열 값 중 그 값이 null이 아닌 행을 찾을 수 있습니다. 위의 코드는 불러온 데이터의 "first_name" 열 값 중 null이 아닌 값을 가지는 행만 반환한다는 의미입니다.
df[(df['pre_movie_score'].isnull()) & df['sex'].notnull()]

isnull 함수를 사용하면 열 값 중 그 값이 null인 행을 찾을 수 있습니다. 위의 코드는 불러온 데이터에서 "pre_movie_score" 열 값이 null이고 "sex" 열 값이 null이 아닌 행을 반환한다는 의미입니다.
Dropna( ) 함수
df.dropna()
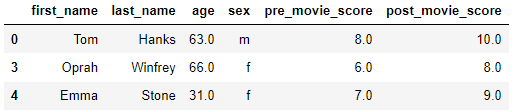
dropna 함수를 사용하면 null을 가진 행 또는 열을 제거할 수 있습니다. 위의 코드는 불러온 데이터에서 null 값을 가진 행을 제거합니다. 만약 df.dropna(axis=1)을 입력하면 null 값을 가진 행이 아닌 열을 제거합니다.
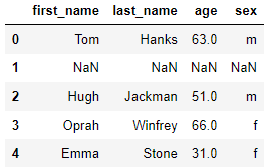
df.dropna(thresh=1)

dropna 함수에는 thresh라는 조건을 설정할 수 있습니다. 위의 예시와 같이 thresh가 1인 경우 정상적인 값이 1개 미만인 행을 제거한다는 의미입니다. 두 번째 행의 경우 null 값이 2개가 있지만 정상적인 값이 4개이므로 해당 행이 제거되지 않았습니다.
df.dropna(thresh=5)

반면 thresh가 5인 경우 두 번째 행에 정상적인 값이 4개 (5개 미만) 이므로 해당 행이 제거되었습니다.
df.dropna(thresh=4,axis=1)
위의 코드를 보면 axis=1 이라는 조건이 있기 때문에 행이 아닌 열을 기준으로 생각해야 합니다. 기존에 있던 "pre_movie_score" 열과 "post_movie_score" 열의 정상적인 값이 4개 미만이기 때문에 해당 열들이 모두 제거되었습니다.
Fillna() 함수
df

fillna 함수를 사용하여 null 값을 특정 값으로 변경할 수 있습니다. 불러온 데이터에서 null 값을 변경해 보겠습니다.
df['first_name'] = df['first_name'].fillna("Empty")
df

df['first_name'].fillna("Empty")는 불러온 데이터의 "first_name"열의 값 중 null 값이 있는 경우 "Empty'로 바꾼다는 의미입니다. 결과를 보면 2번째 행의 first_name 값이 NaN에서 Empty로 변경됐습니다.
df['pre_movie_score'].fillna(df['pre_movie_score'].mean())
df

"pre_movie_score" 열에 있는 null 값도 변경하도록 하겠습니다. 숫자 값일 경우 임의로 값을 입력하는 경우 이후 데이터 분석을 하는 데 문제가 생길 수 있으므로 평균값을 넣어주는 것이 안전한 방법 중 하나입니다. df['pre_movie_score'].fillna(df['pre_movie_score'].mean())는 pre_movie_score 열에 null 값이 있는 경우 해당 열의 평균값으로 변경한다는 의미입니다. 결과를 보면 두 번째와 세 번째 행에 평균값인 7.0이 추가된 것을 확인할 수 있습니다.
Pandas 활용도 높은 함수
Pandas에는 다양한 함수가 있습니다. 그중에서 활용도가 높은 함수 몇 가지를 알아보도록 하겠습니다. CSV 파일 불러오기 df = pd.read_csv('tips.csv') Jupyter Notebook을 사용하는 경우, 불러오고자 하는 CSV
thespud.kr
Pandas Apply 함수 (2)
이전 글에 이어 apply 함수에 대하여 더 알아보도록 하겠습니다. apply와 함께 자주 사용되는 lambda 함수와 lambda 함수 대신 사용할 수 있는 vectorize 함수도 함께 알아보도록 하겠습니다. 해당 글을 보
thespud.kr
Pandas Apply 함수 (1)
Pandas 함수 중 Apply 함수를 사용하면 새롭게 계산된 데이터 또는 조건에 따른 데이터를 가진 열을 쉽게 추가할 수 있습니다. CSV 파일 불러오기 df = pd.read_csv('tips.csv') Jupyter Notebook을 사용하는 경우,
thespud.kr
'데이터 분석' 카테고리의 다른 글
| 판다스 데이터프레임 합치기 (concat, merge) (2) | 2024.01.27 |
|---|---|
| Pandas 피벗 테이블 만들기 (2) | 2024.01.20 |
| Pandas 활용도 높은 함수 (0) | 2024.01.14 |
| Pandas Apply 함수 (2) (0) | 2024.01.13 |
| Pandas Apply 함수 (1) (1) | 2024.01.13 |



