
데이터 분석을 하다 보면 다른 데이터프레임을 서로 합쳐야 하는 경우가 있는데요, 판다스로 다른 데이터프레임을 합치는 방법에 대하여 알아보도록 하겠습니다. 출발합니다!
데이터 준비 1
data_one = {'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']}
data_two = {'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}
one = pd.DataFrame(data_one)
two = pd.DataFrame(data_two)
먼저 임의로 데이터프레임 두 개 (one과 two)를 만들어 줍니다.
one

two

Concat ( ): 행을 기준으로 합치기
A = pd.concat([one,two],axis=0)
A
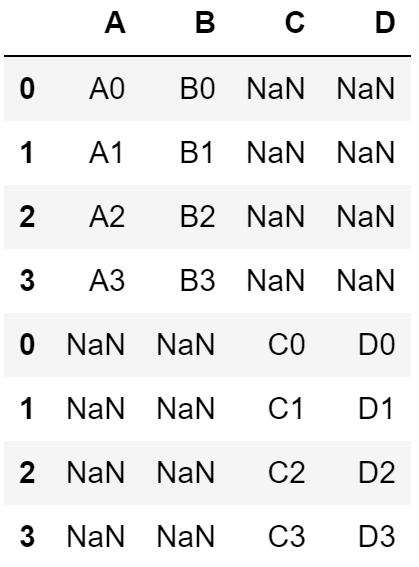
concat 함수를 이용하면 다른 데이터프레임을 서로 합칠 수 있습니다. pd.concat([one,two],axis=0)는 one과 two 테이블을 행 (axis = 0) 기준으로 합친다는 의미입니다.
Concat ( ): 행을 기준으로 합치기
B = pd.concat([one,two],axis=1)
B

열을 기준으로 합치고 싶다면 pd.concat([one,two],axis=1)와 같이 axis 값을 0이 아닌 1로 입력하면 됩니다.
Concat ( ): 행을 기준으로 합치기, 열 이름 일
two.columns = one.columns
pd.concat([one,two])
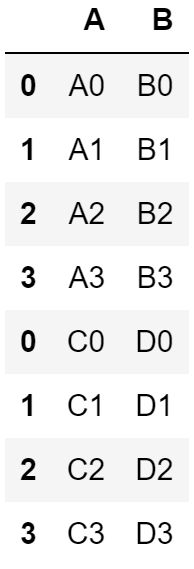
위에서는 각 데이터프레임에 있는 열 이름이 다르기 때문에 행을 기준으로 합치니 Null 값이 생겼습니다. Null 값을 없애고 싶으면 two.columns = one.columns와 같이 각 데이터프레임의 열 이름을 같게 만들어주고 다시 행을 기준으로 합치면 됩니다.
데이터 준비 2
C = pd.DataFrame({'reg_id':[1,2,3,4],'name':['Andrew','Bobo','Claire','David']})
D = pd.DataFrame({'log_id':[1,2,3,4],'name':['Xavier','Andrew','Yolanda','Bobo']})
먼저 임의로 데이터프레임 두 개 (C와 D)를 만들어 줍니다.
C

D

Merge( ) _ Inner Join
pd.merge(C,D,how='inner',on='name')

merge 함수를 사용해도 다른 데이터프레임을 합칠 수 있습니다. concat과는 다르게 합치는 방식을 지정할 수 있습니다. pd.merge(c,d,how='inner',on='name')는 c와 d 데이터프레임을 합치는데 두 테이블에 공통으로 존재하는 (how = 'inner') 이름 (on = 'name')을 기준으로 합친다는 의미입니다. c와 d 데이터프레임에 공통으로 존재하는 이름은 Andrew와 Bobo이기 때문에 합쳐진 데이터프레임에는 2개의 행만 있습니다.
Merge( ) _ Left Join
pd.merge(c,d,how='left',on='name')
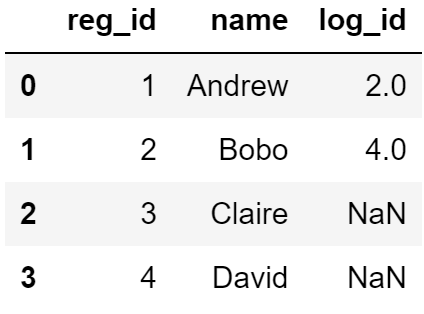
left join (how = 'left')은 합치는 데이터프레임 중 먼저 지정한 데이터프레임 (c)을 기준으로 다음 데이터프레임 (d)을 합친다는 의미입니다. merge는 기본적으로 고유값을 가지는 열 (id와 같이 중복이 없는 값)을 기준으로 데이터프레임을 합치기 때문에 고유값을 가지는 열이 2개 이상이 아닌 경우 입력하지 않아도 됩니다. 사용 중인 두 테이블에 고유값을 가진 열은 name 밖에 없기 때문에 on = 'name'은 생략해도 됩니다.
Merge( ) _ Right Join
pd.merge(c,d,how='right',on='name')

right join (how = 'right')은 합치는 데이터프레임 중 이후 지정한 데이터프레임 (d)을 기준으로 먼저 지정한 데이터프레임 (c)을 합친다는 의미입니다.
Merge( ) _ Outer Join
pd.merge(c,d,how='outer',on='name')

outer join (how = 'outer')은 기준 데이터프레임에 상관없이 양쪽 데이터프레임의 데이터가 모두 합쳐지도록 합니다.
Pandas 피벗 테이블 만들기
데이터프레임의 데이터가 복잡하고 많으면 원하는 정보를 얻기 힘듭니다. 데이터를 정렬하여 원하는 정보를 빨리 찾기 위해서 피벗 테이블을 활용할 수 있습니다. 판다스의 피벗 테이블은 엑셀
thespud.kr
Pandas Null값 관련 함수
데이터분석을 할 때 가장 방해되는 요소 중 하나가 Null값 입니다. 특히, 숫자의 계산이 필요한 경우 null값은 계산의 부정확성을 증가시킵니다. 임의로 값을 변경할 경우 정확한 분석을 할 수 없
thespud.kr
Pandas 활용도 높은 함수
Pandas에는 다양한 함수가 있습니다. 그중에서 활용도가 높은 함수 몇 가지를 알아보도록 하겠습니다. CSV 파일 불러오기 df = pd.read_csv('tips.csv') Jupyter Notebook을 사용하는 경우, 불러오고자 하는 CSV
thespud.kr
Pandas Apply 함수 (1)
Pandas 함수 중 Apply 함수를 사용하면 새롭게 계산된 데이터 또는 조건에 따른 데이터를 가진 열을 쉽게 추가할 수 있습니다. CSV 파일 불러오기 df = pd.read_csv('tips.csv') Jupyter Notebook을 사용하는 경우,
thespud.kr
'데이터 분석' 카테고리의 다른 글
| 파이썬 사이킷런 (Scitkit-Learn)과 선형회귀 모델 (1) (2) | 2024.02.03 |
|---|---|
| Matplotlib 기본 라인 그래프 만들기 (2) | 2024.01.31 |
| Pandas 피벗 테이블 만들기 (2) | 2024.01.20 |
| Pandas Null값 관련 함수 (0) | 2024.01.20 |
| Pandas 활용도 높은 함수 (0) | 2024.01.14 |



